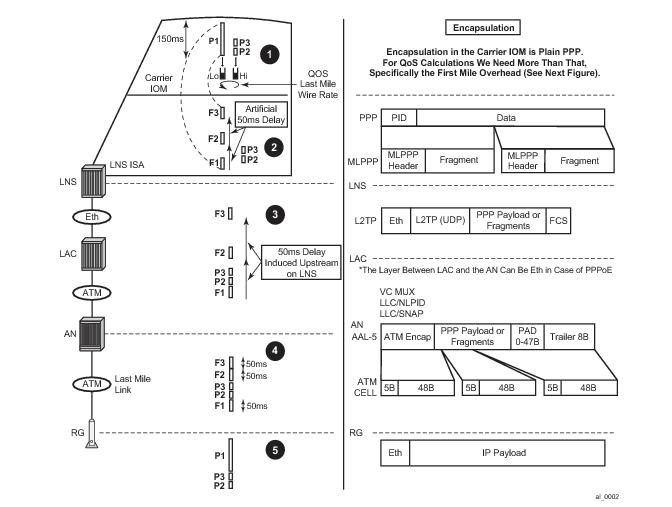
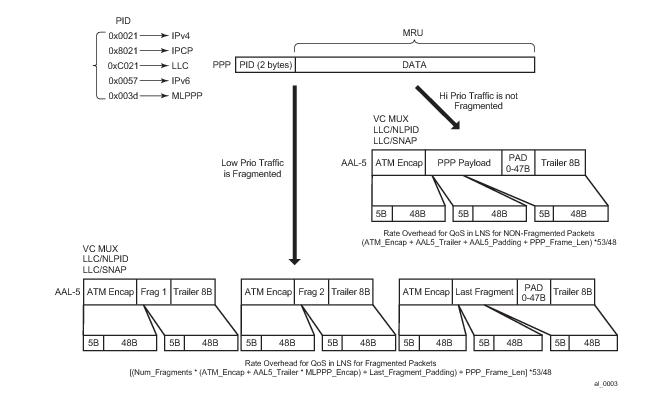
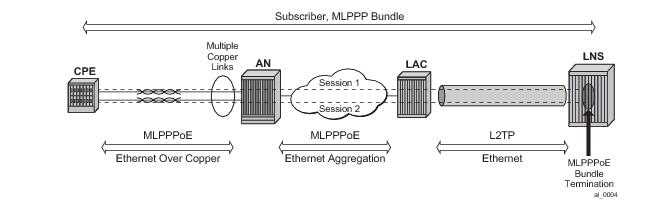
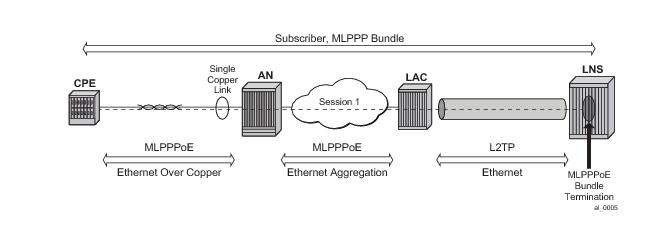
|

|

|

|

|
| For feedback, use the following: |
| ipd_online_feedback@alcatel-lucent.com |
|
|
|
|
|
|